Meetup
I went to the Miro headquarter in Amsterdam to attend my first DuckDB meetup 🦆
![]()
DuckDB
DuckDB is a very powerful and easy-to-use in-memory database.
Here Hannes Mühleisen - one of the creators - compared DuckDB to a burger 🍔 - I guess here no puns intended.

The point being that DuckDB cares a lot about the user experience, in addition to the 'core' which is the RDBMS part.
A personal experiment
I have known DuckDB since one year and tried it out some months ago for a personal project.
I set up a simple CLI with Typer where I had this query command that would:
Execute the various SQL queries via DuckDB and save the output to CSV files.
The code was the following:
In __init__.py
def main() -> None:
"""Execute the various SQL queries via DuckDB and save the output to CSV files."""
# Import inside the command function, so that the command is fast and responsive
# when calling `--help` and will instead only load libraries when it's needed
# to carry out an action.
from .constants import QUERIES_TO_OUTPUT_FILES
from .utils import (
execute_query_and_save_output_to_file,
set_up_database_with_tables,
)
connection = set_up_database_with_tables()
[
execute_query_and_save_output_to_file(
connection=connection,
query=query["query"],
output_file=query["output_file"],
)
for query in QUERIES_TO_OUTPUT_FILES
]
Then in utils.py
import duckdb
from scripts.commands.common.constants import MAP_TABLE_NAME_TO_FILE_PATH
from scripts.commands.common.logging import logger
def set_up_database_with_tables(
files: list[dict] = MAP_TABLE_NAME_TO_FILE_PATH,
) -> duckdb.DuckDBPyConnection:
"""Sets up the database.
NOTE: This will:
* Create a connection.
* Create the tables from given .CSV files.
"""
connection = duckdb.connect()
logger.info("Setting up the database...")
[
(
connection.execute(
f"CREATE TABLE {file['table_name']} AS SELECT * FROM read_csv_auto('{file['file_path']}')"
),
logger.info(
f"Table {file['table_name']} created from {file['file_path']}."
),
)
for file in files
]
return connection
def execute_query_and_save_output_to_file(
connection: duckdb.DuckDBPyConnection, query: str, output_file: str
) -> None:
"""Execute the query and save the result to a CSV file."""
connection.execute(query)
connection.execute(f"COPY ({query}) TO '{output_file}' (HEADER, DELIMITER ',')")
logger.info(f"Saved the output to {output_file}")
A query example was like this one:
_GET_TOP_THREE_COUNTRIES_WITH_THE_MOST_AIRPORTS_QUERY = """
SELECT countries.name as country_full_name, airports.iso_country AS iso_country_code, COUNT(iso_country) AS number_of_airports
FROM airports
LEFT JOIN countries on countries.code = airports.iso_country
WHERE airports.type IN ('small_airport', 'medium_airport', 'large_airport') -- Assumption: Only interested in small, medium, and large airports
AND airports.type NOT IN ('heliport', 'closed', 'seaplane_base', 'balloonport') -- Assumption: Exclude heliports, closed airports, seaplane bases, and balloonports
GROUP BY country_full_name, iso_country_code
ORDER BY number_of_airports DESC
LIMIT 3
"""
If I look at the pyproject.toml, I also see: duckdb = "^0.10.0" - I am sure many things improved in the time-being!
What is new
Something that I learned at the Meetup of course involves LLMs ✨
Specifically, there was a cool presentation from MotherDuck on text to SQL. You just write in natural language what you want, and the LLM outputs SQL.
For example:
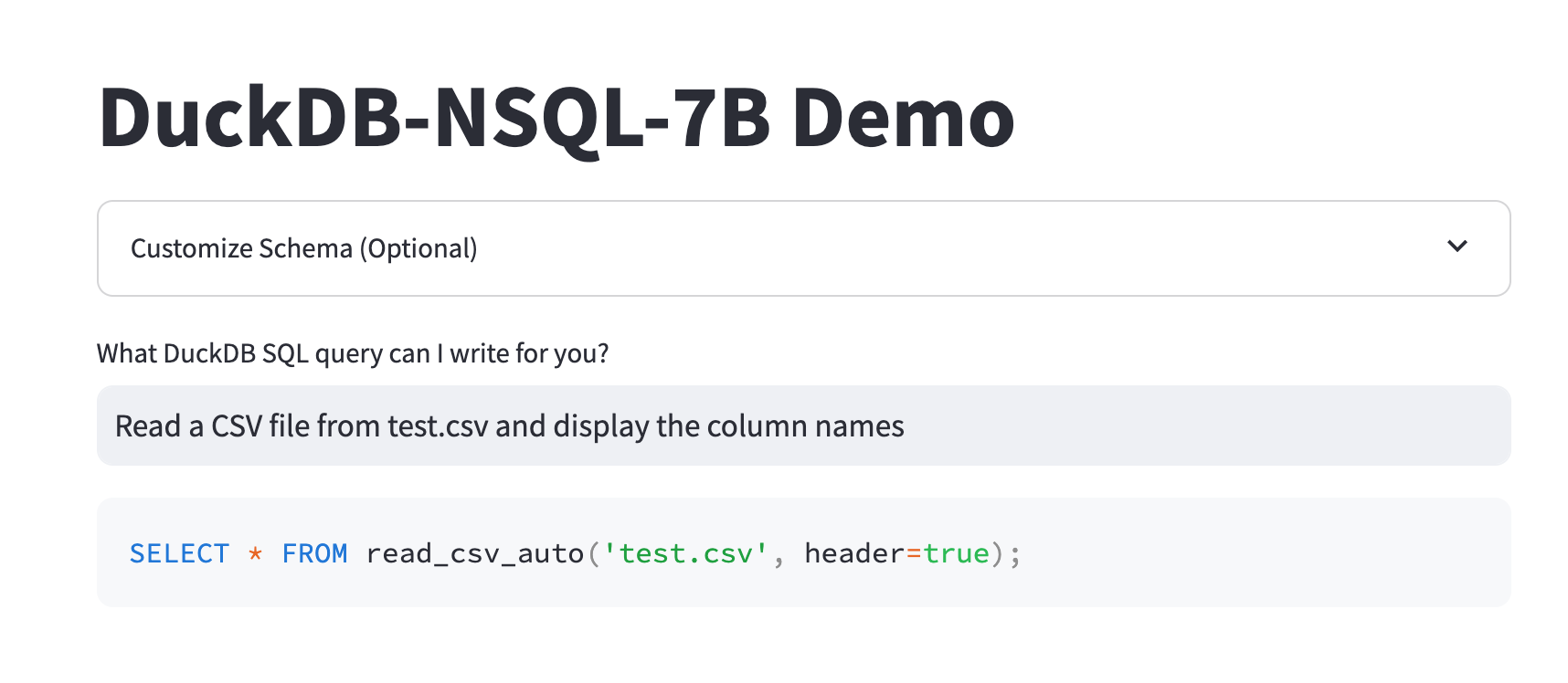
This is very nice and a very good starting point when you want to start out with a query. It builds up from the already interesting work that they did on FixIt.
Conclusion
The naming can be confusing, but these all worth checking out:
- DuckDB - the database
- DuckDB Labs - the support/consulting firm
- MotherDuck - the data warehouse